vRealize Operations Manager (vROPS) is well known monitoring tool that provides recommendations, alerts, reports, and dashboards to display how the environment is performing. In this post I will not go into features, nor operational part of this solution, but rather focus on its components and architecture. It is designed to be highly scalable, built upon Gemfire cluster technology, currently enabling the cluster to scale-out up to 16 nodes. For vROPS there are two primary types of nodes:
- Analytics nodes – performs analysis and data collection.
- Remote collectors – deployed in a remote datacenter, sends data to analytic nodes, does not store data or provide analysis itself.
Each node consists of several layers:
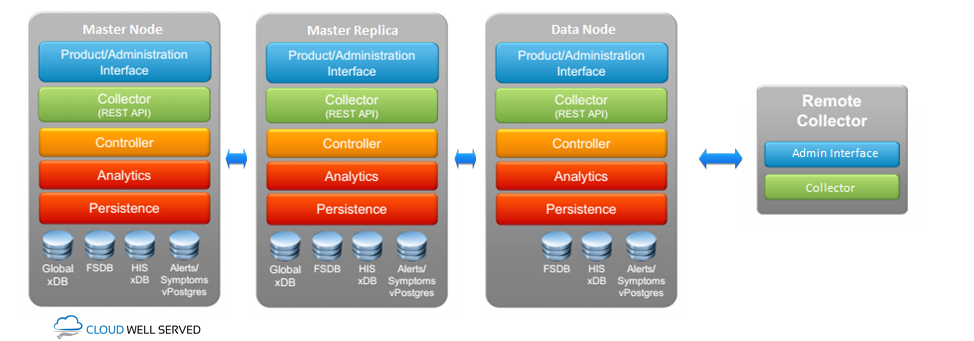
- Administration and product interface – user connects to administration interface, product interface communicates with the controller component to retrieve information, store information, and start actions.
- Collector – responsible for for capturing the data coming through the adapters. Adapters connect to external systems and collect properties and metrics from objects using whatever connection mechanisms are available.
- Controller – responsible for mapping the collected data to the right resources and also retrieving the data for the request queries.
- Analytics – receives data from the controller component, caches the collected data, and processes them.
- Persistence – persist data to disk.
- Databases:
- FSDB – this database is available on all nodes and stores all the collected metrics in raw format.
- Historical xDB – stores the historical inventory service data, and is only on master/replica node or first node of the vROPs cluster.
- Global xDB – stores the user configuration data, like alerts and alarms, and is only available on the master/replica or the first node of vROPs cluster.
- vPostgres – contains alerts and symptoms information.
Analytics cluster
The analytics nodes participate in the vROPS cluster. There are three distinct sub-type:
- Master node – first node assigned to a cluster. The master node is also responsible for managing all the other nodes in the cluster.
- Data nodes – used to expand the capacity of the cluster. A data node has adapters installed and can perform collection and analysis.
- Replica node – backup to the master node should the master node fail.
Remote collectors
Remote Collector node can be used in a remote datacenter location to send data to analytics cluster. Remote collectors do not buffer data while the network is experiencing a problem. If the connection between remote collector and analytics cluster is lost, the remote collector does not store data points that occur during that time. In turn, and after the connection is restored, vROPS does not retroactively incorporate associated events from that time into any monitoring or analysis.
A collection of analytics nodes and remote collectors can create a collector group. You can assign adapters to a collection group instead of a single node. When you do that, the adapter can use any collector in the group. It helps to achieve adapter resiliency in cases the collector experiences network interruption or becomes unavailable. If this occurs, and the collector is part of a group, the total workload is redistributed among all the collectors in the group, reducing the workload on each collector.
All the nodes types and node components are shown on picture below:
Like!! Great article post.Really thank you! Really Cool.